这是我参与「第五届青训营」伴学笔记创作活动的第 7 天
前言
举个例子,你现在有一个全栈的项目,团队里写了前端、后端、使用文档和一个工具库。
一般情况的话,我们会创建四个仓库,放不同的内容,其中前端如果使用工具库的话,我们会在前端里引入工具库的包(可能是直接,可能是在 npm 上 publish 过的)
你希望运行前端项目的时候,同时运行三个命令(例如使用 yarn)你需要运行 yarn lint 、 yarn build 、 yarn serve 你需要敲三个命令,很麻烦。
MonoRepo
什么是 MonoRepo
在开发场景中,我们希望各个项目之间能够足够的独立,各自的开发和发布不会产生太多的耦合,现在很多的项目也是出于这种考虑去拆成一个一个独立的子项目,在单独的代码仓库中进行管理,这就是我们常见的单代码仓库的开发模式。
例如我们 前言中举的例子,你想要前端项目中使用工具库中的包,你需要到前端,或者使用 npm publish 后再安装,当你工具库的版本更新的时候,你需要把前端项目里的工具库版本也更新掉。
如果把所有有依赖关系的代码都放到一个仓库中进行统一维护,当一个库变动时,其它的代码能自动的进行依赖升级,那么就能精简开发流程、提高开发效率。这种多包的代码仓库管,就是 MonoRepo。
其实 TurboRepo 在前端中非常常见,Babel、React、Vue 等开源项目都是使用这种方式在管理代码,其中 Babel 官方开源的多包管理工具 Lerna 也被广泛的使用。
这次我介绍的是 TurboRepo。
TurboRepo
TurboRepo 是一个适用于 JavaScript 和 Typescript TurboRepo 的高性能构建工具,使用 go、rust 语言编写,性能很好。
优势
增量构建:缓存构建内容,并跳过已经计算过的内容,通过增量构建来提高构建速度
内容 hash:通过文件内容计算出来的 hash 来判断文件是否需要进行构建,缓存在云端,登录即可享受
云缓存:可以和团队成员共享 CI / CD 的云构建缓存,来实现更快的构建
多任务并行执行:在不浪费空闲 CPU 的情况下,以最大并行数量来进行构建
任务管道:通过定义任务之间的关系,让 TurboRepo 优化构建的内容和时间
约定式配置:通过约定来降低配置的复杂度,只需要几行简单的 JSON 就能完成配置(配置 turbo.json)
开始使用
对于一个新的项目,可以运行下面的命令来生成全新的代码仓库
npx create-turbo@latest对于一个已经存在的 monorepo 项目,可以通过下面的步骤来接入 turborepo
安装 Turborepo
将 Turborepo 添加到项目最外层的 devDependecies 中
npm install turbo -D
or
yarn add turbo --dev创建任务管道
在 package.json 的 turbo 中,将想要 "turbo" 的命令添加到管道中 管道定义了 npm 包中 scripts 的依赖关系,并且为这些命令开启了缓存。这些命令的依赖关系和缓存设置会应用到 monorepo 中的各个包中
{
"turbo": {
"pipeline": {
"build": {
"dependsOn": ["^build"],
"outputs": [".next/**"]
},
"test": {
"dependsOn": ["^build"],
"outputs": []
},
"lint": {
"outputs": []
},
"dev": {
"cache": false
}
}
}
}上面的示例中, build 和 test 这两个任务具有依赖性,必须要等他们的依赖项对应的任务完成后才能执行,所以这里用 ^ 来表示。 对于每个包中 package.json 中的 script 命令,如果没有配置覆盖项,那么 Turborepo 将缓存默认输出到 dist/** 和 build/** 文件夹中。
pipeline
从上面的 turbo 的配置中可以看出来,管道 (pipeline) 是一个核心的概念,Turborepo 也是通过管道来处理各个任务和他们的依赖关系的。
Turborepo 提供了一种声明式的方法来指定各个任务之间的关系,这种方式能够更容易理解各个任务之间的关系,并且 Turborepo 也能通过这种显式的声明来优化任务的执行并充分调度 CPU 的多核心性能。
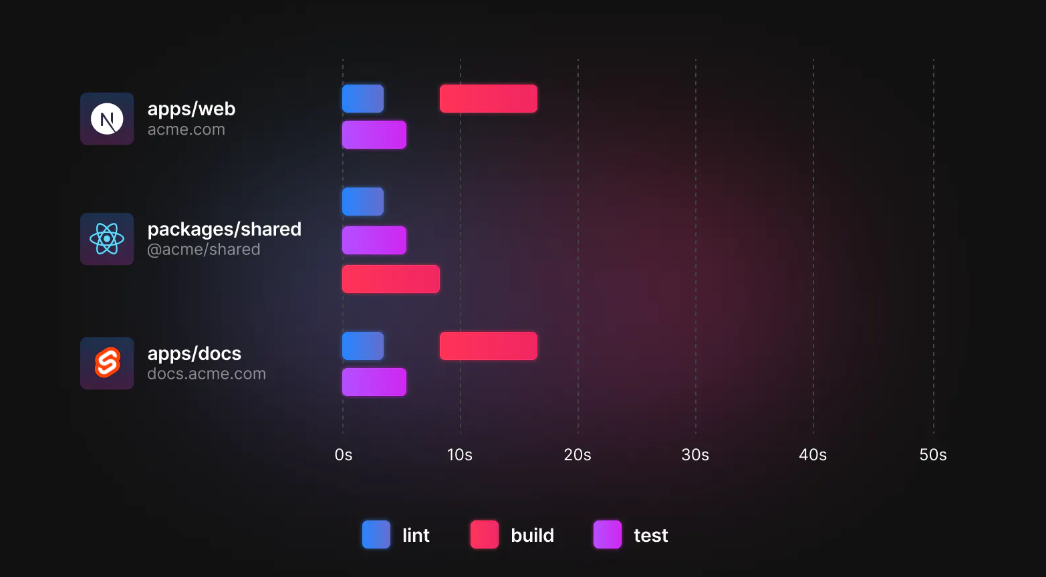
配置 pipeline
pipeline 中每个键名都可以通过运行 turbo run 来执行,并且可以使用 dependsOn 来执行当前管道的依赖项。
上图的执行流程,可以配置成如下的格式
{
"turbo": {
"pipeline": {
"build": {
"dependsOn": ["^build"],
},
"test": {
"dependsOn": ["build"],
"outputs": []
},
"lint": {
"outputs": []
},
"deploy": {
"dependsOn": ["build", "test", "lint"]
}
}
}
}通过 dependsOn 的配置,可以看出各个命令的执行顺序:
- 因为 A 和 C 依赖于 B,所以包的构建存在依赖关系,根据 build 的 dependson 配置,会先执行依赖项的 build 命令,依赖项执行完后才会执行自己的 build 命令。从上面的瀑布流中也可以看出,B 的 build 先执行,执行完以后 A 和 C 的 build 会并行执行
- 对于 test,只依赖自己的 build 命令,只要自己的 build 命令完成了,就立即执行 test
- lint 没有任何依赖,在任何时间都可以执行
- 自己完成 build、test、lint 后,再执行 deploy 命令
可以通过下面的命令执行:
npx turbo run test build lint deploy常规依赖
如果一个任务的执行,只依赖自己包其他的任务,那么可以把依赖的任务放在 dependsOn 数组里
{
"turbo": {
"pipeline": {
"deploy": {
"dependsOn": ["build", "test", "lint"]
}
}
}
}特定依赖
在一些场景下,一个任务可能会依赖某个包的特定的任务,这时候我们需要去手动指定依赖关系。
{
"turbo": {
"pipeline": {
"build": {
"dependsOn": ["^build"],
},
"test": {
"dependsOn": ["build"],
"outputs": []
},
"lint": {
"outputs": []
},
"deploy": {
"dependsOn": ["build", "test", "lint"]
},
"frontend#deploy": {
"dependsOn": ["ui#test", "backend#deploy"]
}
}
}
}Remote cache
当多人开个一个项目的时候,团队的成员可以共享构建的缓存,从而加快项目的构建速度。
当一个成员把某个分支构建的缓存文件推送到远程的 git 仓库是,另一个成员如果在同一个分支上进行开发,那么 Turborepo 可以支持你去选择某个成员的构建缓存,并在运行相关的构建任务时,从远端拉去缓存文件到本地,加快构建的速度
运行 npx turbo link,进行登录后,就可以选择要使用的缓存
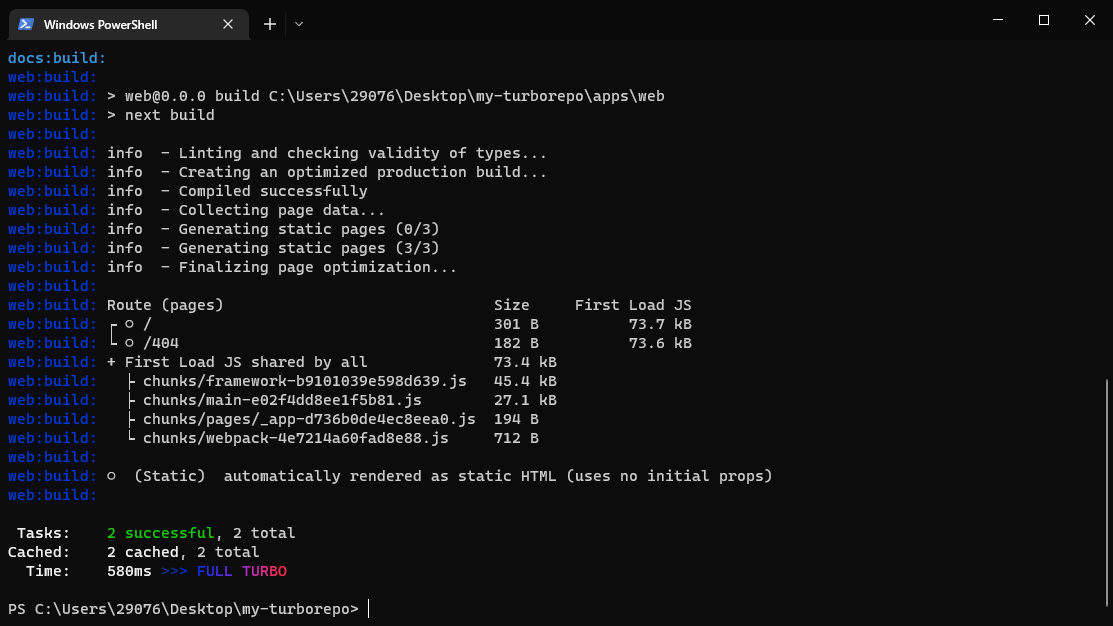
显示 full turbo 则证明匹配到了云端的缓存,直接拉下来不再构建一遍
结尾
我相信 Turborepo 的出现在不久的将来一定会成为 Monorepo 工具链中重要的一环,无论是构建缓存功能还是基于 pipeline 的智能任务调度系统,都非常优秀的解决了传统 Monorepo 存在 “慢” 的问题。
为了更好的性能,大部分人将不再局限于使用 JavaScript 开发 JavaScript 工具,而是更愿意选择其他高门槛语言。
我感觉使用 turbo 有很好的体验,但他好像对 nuxt 兼容性不好,只兼容自己的亲儿子 next🤣。
参考
https://juejin.cn/post/7051929587852247077https://juejin.cn/post/7048234698048274469https://juejin.cn/post/7129267782515949575
https://github.com/vercel/turbo
https://turbo.build/repo/docs/core-concepts/monorepos/running-tasks